
network parameters(IP address, DNS settings, ) directly to devices. Now, with NetworkManager, things are different :
disabled as expected ● irqbalance.service - irqbalance daemon Loaded: loaded (/lib/systemd/system/irqbalance.service; disabled; vendor preset: enabled) Active: inactive (dead) as expected Jun 26 10:31:33 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:31:43 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:31:53 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:32:03 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:32:13 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:32:23 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:32:33 myServer /usr/sbin/irqbalance[PID]: WARNING, didn't collect load info for all cpus, balancing is broken Jun 26 10:32:40 myServer systemd[1]: Stopping irqbalance daemon... Jun 26 10:32:40 myServer systemd[1]: Stopped irqbalance daemon.
Jun 24 13:47:23 localhost systemd-journal[155]: Suppressed 15460 messages from /system.slice/...This can be configured with RateLimitBurst and RateLimitIntervalSec (source).
It all takes place in /etc/systemd/journald.conf
| Directive | Default value | Description |
|---|---|---|
| Compress=boolean | yes | data objects that shall be stored in the journal and are larger than a certain threshold are compressed before they are written to the file system |
| MaxFileSec=rotationPeriod | 1 month |
Normally, time-based rotation should not be required as size-based rotation with options such as SystemMaxFileSize should be sufficient to ensure that journal files do not grow without bounds. However, to ensure that not too much data is lost at once when old journal files are deleted, it might make sense to change this value from the default. |
| MaxLevelStore=level | 7 (debug) | Controls the maximum log level of messages that are stored on disk, forwarded to syslog, kmsg, the console or wall (if enabled). As argument, takes one of :
|
| MaxRetentionSec=logfileTimeToLive | 0 (i.e. : "disabled") |
Normally, time-based deletion of old journal files should not be required as size-based deletion with options such as SystemMaxUse should be sufficient to ensure that journal files do not grow without bounds. However, to enforce data retention policies, it might make sense to change this value from the default. |
| RateLimitBurst=nbMessages | 1000 messages |
|
| RateLimitIntervalSec=intervalDuration | 30s | |
| SplitMode=value | uid | Controls whether to split up journal files per user (only in Storage=persistent mode). value is one of :
|
| Storage=value | auto | Controls where to store journal data. value is one of :
|
| SystemMaxUse=value | Enforce size limits on the journal files
|
SystemMaxUse=1168664K
1269780 KB
(nothing)
SystemKeepFree=584332K
2337328
SystemMaxUse 1168664
SystemKeepFree 584332
totalJournalValues 1752996
fsSize 2337328
extraSize 584332 this is >0 : OK
| Flag | Type | Default | Usage |
|---|---|---|---|
| dyndns_update | boolean | True |
|
| dyndns_update_ptr | boolean | True |
|
period delay job-identifier command
@period_name delay job-identifier command
There's not a lot to say about CRON : it's there, it works. I can't remember a single time having to fiddle with it. Actually, all the magic lies in crontab.
CRON (/usr/sbin/cron) is the clock daemon : it executes commands at specific times. These commands are stored in configuration files called CRON-tables
, aka crontabs. Each user may have his own crontab. crontabs can be found at /var/spool/cron/crontab/userName.
crontabs files mustn't be edited manually, use the crontab utility instead.
As said by the title, tips given in this chapter are quick and dirty and may be wrong or NOT adapted for a permanent configuration, but they COULD save your life for short-term actions. Use at your own risk.
<directory ...> blocks (source) :Even though the configuration parser will forbid having 2 <directory ...> blocks referring to the very same directory, it MAY be possible to create 2 conflicting configurations for the same directory using wildcards :
<directory /path/to/dir>
<directory /path/*/dir>
In such situations, the section which appears later in the config file wins.
I've also experienced configs such as:
<directory /path/to/dir1> config set 1 <directory /path/to/dir1/dir2> config set 2where config set 2 wasn't enabled until config set 1 was commented .
| OS | Configuration files |
|---|---|
| Red Hatoids | /etc/rsyslog.conf |
| Debianoids | /etc/syslog-ng/syslog-ng.conf |
The /etc/rsyslog.conf file is 2-columned, making a kind of source-destination list for logs (source) :
facility1.severity;facility2.severity logfile1 facility3.severity;facility4.severity logfile2 facility1.severity logfile3
apt-get install incron
incron is started right after installation, but you can /etc/init.d/incron start|stop|restart|reload|force-reload|status
| Event name | Triggered when... | Returns name of affected file when monitoring directory |
|---|---|---|
| IN_ACCESS | File was accessed (read) | |
| IN_ATTRIB | Metadata changed, e.g., permissions, timestamps, extended attributes, link count (since Linux 2.6.25), UID, GID, etc. | |
| IN_CLOSE_WRITE | File opened for writing was closed | |
| IN_CLOSE_NOWRITE | File not opened for writing was closed | |
| IN_CREATE | File/directory created in watched directory | |
| IN_DELETE | File/directory deleted from watched directory | |
| IN_DELETE_SELF | Watched file/directory was itself deleted | |
| IN_MODIFY | File was modified | |
| IN_MOVE_SELF | Watched file/directory was itself moved | |
| IN_MOVED_FROM | File moved out of watched directory | |
| IN_MOVED_TO | File moved into watched directory | |
| IN_OPEN | File was opened | |
| IN_ALL_EVENTS | Any event from the list above |
$ characterfileOrDirectoryToMonitor eventToDetect action
/tmp IN_CREATE /tmp/$%_$#
dc_eximconfig_configtype='satellite' dc_other_hostnames='hostname.example.com' dc_local_interfaces='127.0.0.1' dc_readhost='example.com' dc_relay_domains='' dc_minimaldns='false' dc_relay_nets='' dc_smarthost='smtp.example.com' CFILEMODE='644' dc_use_split_config='false' dc_hide_mailname='true' dc_mailname_in_oh='true' dc_localdelivery='mail_home'
Upstart is being obsoleted by systemd.
status of a daemon : initctl status ssh stop Samba : initctl stop smbd status | start | stop | restart | reload list known daemons : - initctl list initctl list | grep start config files : /etc/init/* upstart events : http://ubuntuforums.org/showthread.php?s=3f0e10960bf7fb598136ff1a1308eedf&t=723896&page=2 the event "local-filesystems" is fired once local FS are mounted (?) ======================8<================================================= http://geeknme.wordpress.com/2009/10/15/getting-started-with-upstart-in-ubuntu/ Upstart -provides the cmd 'initctl' -upstart uses .conf files in the /etc/init directory as scripts instead of the ones in /etc/init.d http://upstart.ubuntu.com/wiki/Stanzas http://upstart.ubuntu.com/getting-started.html - Jobs are defined in files placed in /etc/init, the name of the job is the filename under this directory without the .conf extension. They are plain text files and should not be executable. - All job files must have either an exec or script stanza. This specifies what will be run for the job : - exec + args (binary) - script +args (shell script executed by /bin/sh) - initctl list => list of current jobs
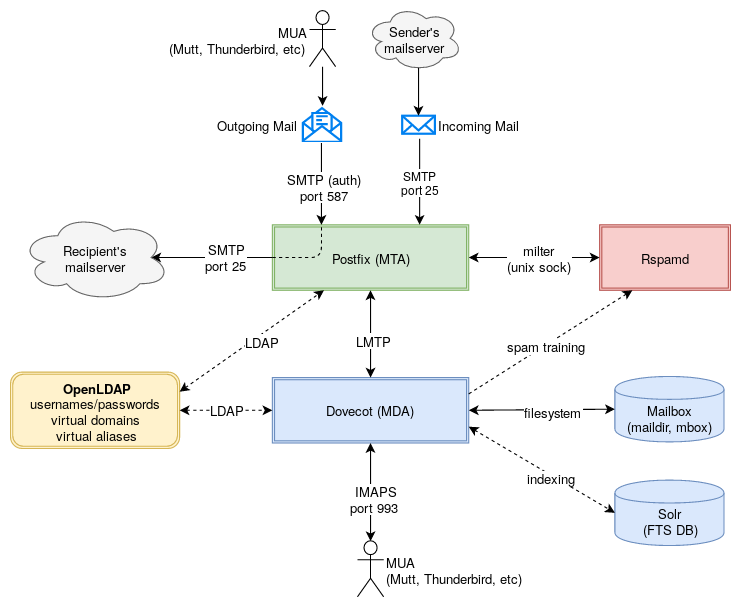
[]" in /etc/postfix/main.cf :
relayhost = [192.168.3.112]