
\K and not include it in $&
echo foobar | perl -pe 'and return :s/(foo)bar/$1/g;' echo foobar | perl -pe 's/foo\Kbar//g;' but this one is much more efficient
I still have to figure how the regex is processed : echo foobar | perl -pe 's/foo\Kbar//g;' foo - get the 'foobar' input string - read the 'foo\Kbar' regex as the "search" part of the 's///' command - because of the \K, it "holds" (forgets ?) anything matched before : i.e. the 'foo' part - remains the 'bar' part - the 's///' command becomes : 's/bar//', i.e. "remove 'bar'" echo 'foobar' | grep -oP 'foo\Kbar' bar - looks like it does the opposite of the example above, but it's not ;-) - 'foo\Kbar' can be understood as "forget 'foo', keep 'bar'" - in the example above, this is provided as the "search" part of an 's///' command : replace 'bar' with nothing, i.e. keep 'foo' - in this example, it is what's happening : grep [options] ""forget 'foo', keep 'bar'"" : outputs 'bar'
<data> <key name="foo"> <value>ga bu</value> </key> <key name="bar"> <value>zo meu</value> </key> </data>from which I'd like to extract the highlighted values.
cat << EOF | sed -r -e 's/</\n</g' -e 's/>/>\n/g' | sed -r '/(^[[:blank:]]*$|[<>])/ d' <data> <key name="foo"> <value>ga bu</value> </key> <key name="bar"> <value>zo meu</value> </key> </data> EOF
ga bu zo meu
cat << EOF | grep -oP '<value>\K[^<]+'
<data>
<key name="foo">
<value>ga bu</value>
</key>
<key name="bar">
<value>zo meu</value>
</key>
</data>
EOF
ga bu zo meu
The magic here is that'<value>\K[^<]+'is interpreted as : - focus on what comes after<value>- match any sequence of characters until you find a<
"ansible_facts": {
...
"ansible_date_time": {
"date": "2023-10-25",
"day": "25",
"epoch": "1698217860",
"hour": "09",
"iso8601": "2023-10-25T07:11:00Z",
"iso8601_basic": "20231025T091100124951",
"iso8601_basic_short": "20231025T091100",
"iso8601_micro": "2023-10-25T07:11:00.124951Z",
"minute": "11",
"month": "10",
"second": "00",
"time": "09:11:00",
"tz": "CEST",
"tz_offset": "+0200",
"weekday": "Wednesday",
"weekday_number": "3",
"weeknumber": "43",
"year": "2023"
},
...
}
unspecifiedformat
unspecified(aka extended) format : has separators to enhance human readability
- between date values: between time valuesT between date and time valuesZ| GMT | UTC | |
|---|---|---|
| is | a time zone | a time standard |
| is based on | astronomical observations | atomic clocks |
| states 1 second is | 1/86400 of a day, with
This implies that 1 second is not a constant because the Earth rotation is not perfectly regular.
|
the time it takes a caesium 133 atom to do something9,192,631,770 times in a row This never changes.
|
Though conceptually different, I have never seen a computer program where it wasn't OK to regard GMT and UTC as equivalent. They are never more than 1 second off from each other, and computer software very often does not distinguish.
| Context | Single line | Multiple lines | Notes | ||
|---|---|---|---|---|---|
| Starts with ... | Until ... | Starts with ... | Until ... | ||
| ASP | ' |
end of line | |||
| Awk | # |
end of line | source | ||
| Bash, MySQL query | # |
end of line | |||
| C, PHP, Javascript | // |
end of line | /* |
*/ |
|
| CSS | /* |
*/ |
/* |
*/ |
|
| HTML | <!-- |
--> |
<!-- |
--> |
|
| LATEX | % |
end of line | |||
| MS-Dos Batch (.bat, .cmd) | REM |
end of line | |||
| Oracle query | -- |
end of line | |||
| PERL | # |
end of line | =cut |
=cut |
Must include blank lines before and after the comment tag |
| Python | # |
end of line |
|
|
source |
| VBA, VBS | ' |
end of line | |||
| YAML (.yml) | # |
end of line | {# |
#} |
|
1Bh) and the left-bracket character [ (5Bh). The character(s) following the escape and left-bracket characters specify an alphanumeric code that controls a keyboard or display function.ansiCode_start='\033['
ansiCode_stop='m'
black="${ansiCode_start}0;30${ansiCode_stop}"
red="${ansiCode_start}0;31${ansiCode_stop}"
green="${ansiCode_start}0;32${ansiCode_stop}"
orange="${ansiCode_start}0;33${ansiCode_stop}"
blue="${ansiCode_start}0;34${ansiCode_stop}"
purple="${ansiCode_start}0;35${ansiCode_stop}"
cyan="${ansiCode_start}0;36${ansiCode_stop}"
lightGray="${ansiCode_start}0;37${ansiCode_stop}"
darkGray="${ansiCode_start}1;30${ansiCode_stop}"
lightRed="${ansiCode_start}1;31${ansiCode_stop}"
lightGreen="${ansiCode_start}1;32${ansiCode_stop}"
yellow="${ansiCode_start}1;33${ansiCode_stop}"
lightBlue="${ansiCode_start}1;34${ansiCode_stop}"
lightPurple="${ansiCode_start}1;35${ansiCode_stop}"
lightCyan="${ansiCode_start}1;36${ansiCode_stop}"
white="${ansiCode_start}1;37${ansiCode_stop}"
noColor="${ansiCode_start}0${ansiCode_stop}"
printf "I ${red}<3${noColor} Linux\n"
echo -e "I ${red}<3${noColor} Linux"
for color in black red green orange blue purple cyan lightGray darkGray lightRed lightGreen yellow lightBlue lightPurple lightCyan white; do echo -e "${!color}${color}${noColor}"; done
0;.. colors are the regular ones whereas the 1;.. are the light colors. Names don't exactly match : "dark gray" is actually a "light black", and "white" is a "light light gray" echo -e "\033[0;31m___solid_________\033[0m" echo -e "\033[1;31m___bold__________\033[0m" echo -e "\033[2;31m___dark__________\033[0m" echo -e "\033[3;31m___italic________\033[0m" echo -e "\033[4;31m___underlined____\033[0m" echo -e "\033[5;31m___blink slow____\033[0m" echo -e "\033[6;31m___blink fast____\033[0m" echo -e "\033[7;31m___reverse_______\033[0m" echo -e "\033[8;31m___hide__________\033[0m" echo -e "\033[9;31m___strikeout_____\033[0m"
echo -e "\033[41m___on red______\033[0m \t \033[101m___on high intensity red______\033[0m" echo -e "\033[42m___on green____\033[0m \t \033[102m___on high intensity green____\033[0m" echo -e "\033[43m___on yellow___\033[0m \t \033[103m___on high intensity yellow___\033[0m" echo -e "\033[44m___on blue_____\033[0m \t \033[104m___on high intensity blue_____\033[0m"
echo -e "\033[0;34m___solid_________________\033[0m" echo -e "\033[1;34m___bold__________________\033[0m" echo -e "\033[0;94m___high intensity________\033[0m" echo -e "\033[1;94m___bold high intensity___\033[0m"
echo -e "\033[43m\033[1;31m___bright red on yellow_____\033[0m" echo -e "\033[43m\033[5;31m___blinking red on yellow___\033[0m"
Spoiler : you can't .
https://github.com/openambitproject/openambit the device communication lib : libambit http://www.movescount.com/fr/apps ==> http://www.movescount.com/fr/groups/group5135-Linux_User_Group http://sourceforge.net/projects/openambit/ (source : http://forum.ubuntu-fr.org/viewtopic.php?id=1211421) http://openambit.org/forums/topic/ubuntu-14-04/ ==> DEBIAN : https://tracker.debian.org/pkg/openambit http://openambit.org/forums/topic/ubuntu-14-04/#post-164
| step | x | y |
|---|---|---|
| 0 | a | b |
| 1 | = x0 - y0 = a - b |
= y0 = b |
| 2 | = x1 = a - b |
= x1 + y1 = a - b + b = a |
| 3 | = y2 - x2 = a - (a - b) = a - a + b = b |
= y2 = a |
x=123; y=456; echo "BEFORE : x=$x, y=$y"; x=$((x-y)); y=$((x+y)); x=$((y-x)); echo "AFTER : x=$x, y=$y"
 |
 |
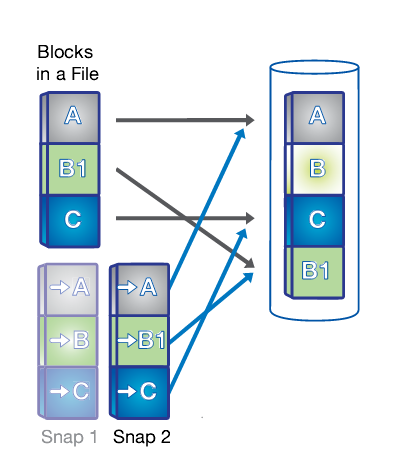 |
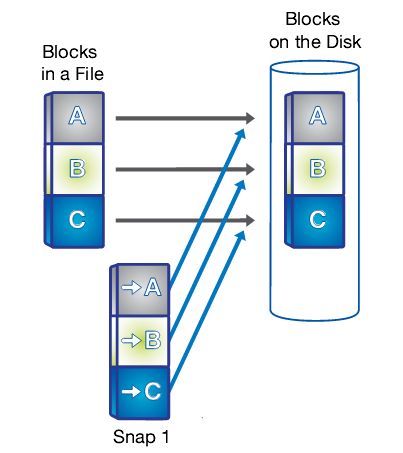
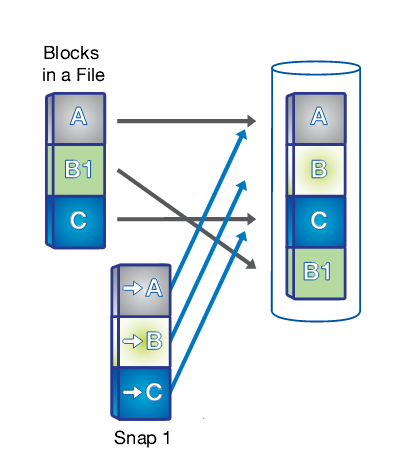
| 1. A snapshot is taken. | 2. Changed data is written to a new block and the pointer is updated, but the snapshot pointer still points to the old block, giving you a live view of the data and an historical view. | 3. Another snapshot is taken and you now have access to 3 generations of your data without taking up the disk space that 3 unique copies would require : live, snapshot 2 and snapshot 1 in order of age. |
| Character | Windows | Linux |
|---|---|---|
| ¡ | AltGr-! | |
| ¼ | ALT + 172 |
|
| ½ | ALT + 171 |
|
| ¾ | ALT + 243 |
|
| ¿ | AltGr-? | |
| À | ALT + 183 |
|
| Â | ALT + 182 |
|
| Ç | ALT + 128 |
|
| È | ALT + 200 |
|
| É | ALT + 144 |
|
| Ê | ALT + 210 |
|
| Ô | ALT + 226 |
|
| ñ | AltGr-~, n | AltGr-^, n |
?, +, {, |, ( and ) have no special meaning\ to become special| BRE | ERE | |
|---|---|---|
literal ( |
( |
\( |
| grouping character | \( |
( |
echo -e "a\nb\nc" | /bin/grep 'b+' (nothing) the+is not special : BRE echo -e "a\nb\nc" | /bin/grep 'b\+' b the+has become "special" : ERE echo -e "a\nb\nc" | /bin/grep -E 'b+' b we've explicitly requested ERE with grep -E
[[ "foo" =~ ^f.o$ ]] && echo match || echo 'no match' match.matches a single character (o,., ) [[ "foo" =~ ^f\.o$ ]] && echo match || echo 'no match' no match\.does NOT match any single character [[ "f.o" =~ ^f\.o$ ]] && echo match || echo 'no match' match\.matches a., showing that =~ uses ERE
| Expression | Matches | Example | Details | ||||||
|---|---|---|---|---|---|---|---|---|---|
. |
any single character | dot / point / period . |
|||||||
+ |
the preceding item (expression or character) repeated at least 1 time | + sign |
|||||||
* |
the preceding item repeated 0 or more times | asterisk * |
|||||||
| |
either what's on the left or what's on the right | alternation | |
|||||||
? |
2 usages :
|
||||||||
^foo |
nothing before foo, ^ = beginning of string |
beginning of string | |||||||
foo$ |
nothing after foo, $ = end of string |
end of string | |||||||
[a-z], [A-Z], [0-9] |
any single character in the range a-z, A-Z, 0-9 |
|
|||||||
[12345] or [1-5] |
any single character in the list : 1, 2, 3, 4, 5 | ||||||||
[^A-Z] |
any single character NOT in the list : everything except capital letters | ||||||||
expression{n} |
|
interval expressions | |||||||
(expression) + \n |
"what was matched by the nth (expression)"
|
|
alias (aka callback or back reference) used by sed and by Emacs (in replace regexp mode)
parenthesis have different meanings depending on the context (BRE vs ERE), Emacs requires escaping them :
\( and \) |
||||||
| character classes | |||||||||
[:alpha:] |
alphabetic characters, same as A-Za-z |
|
Character classes are pre-defined lists of characters (i.e. [:digit:] translates into 0123456789). As such, they have to be enclosed between [ and ] brackets :
|
||||||
[:blank:] |
blank characters : space and tab (see \s) |
|
|||||||
| regular expression extensions | |||||||||
|
word boundary (because not all words are separated by space or blank characters) |
|
|||||||
| \d | matches digits | ||||||||
| \D | non-digit characters | ||||||||
\s |
whitespace characters : space and tab (see [:blank:]) |
|
|||||||
y = ax + b
y = ax + b y1 = ax1 + b y2 = ax2 + b b = y1 - ax1 y2 = ax2 + y1 - ax1 y2 = a(x2 - x1) + y1 a(x2 - x1) = y2 - y1 a = ( y2 - y1 ) / ( x2 - x1 ) y1 = ax1 + b b = y1 - ax1 b = y1 - x1 * ( y2 - y1 ) / ( x2 - x1 )
y = ax + b ax + b = n ax = n - b x = ( n - b ) / a
0 for o, | for l, $ for s, ... (which is why P@$$w0rd is plain sh*t )This is an answer to the correct horse battery staple thing.
mom of 3 great kids) was broken thanks to momof3 and gr8kids (which were probably previously broken via brute-force).
foreverto brute-force it, doubling its length won't require crackers to run their programs until infinity twice to break it : if somebody wants your password hard enough, they'll find a way
| Goal | Target people | Method |
|---|---|---|
| Get admin rights on a workstation | Helpdesk |
|
{kind=link}