
| Name | Role | Notes |
|---|---|---|
| Corosync | cluster communication + membership | Often associated with Pacemaker, Corosync is the communication layer. |
| HAProxy | TCP + HTTP reverse proxy |
|
| Heartbeat (1, 2, 3) | cluster communication + membership |
|
| Keepalived | ||
| Pacemaker | CRM | Often associated with Corosync. |
http://www.linux-ha.org http://clusterlabs.org/ https://geekpeek.net/linux-cluster-nodes/ https://www.quora.com/Which-is-a-better-Linux-ip-failover-tool-keepalived-or-heartbeat-pacemaker http://www.formilux.org/archives/haproxy/1003/3259.html a cluster-oriented product such as heartbeat will ensure that a shared resource will be present at *at most* one place. This is very important for shared filesystems, disks, etc... It is designed to take a service down on one node and up on another one during a switchover. That way, the shared resource may never be concurrently accessed. This is a very hard task to accomplish and it does it well. a network-oriented product such as keepalived will ensure that a shared IP address will be present at *at least* one place. Please note that I'm not talking about a service or resource anymore, it just plays with IP addresses. It will not try to down or up any service, it will just consider a certain number of criteria to decide which node is the most suited to offer the service. But the service must already be up on both nodes. As such, it is very well suited for redundant routers, firewalls and proxies, but not at all for disk arrays nor filesystems. ==> The difference is very visible in case of a dirty failure such as a split brain. A cluster-based product may very well end up with none of the nodes offering the service, to ensure that the shared resource is never corrupted by concurrent accesses. A network-oriented product may end up with the IP present on both nodes, resulting in the service being available on both of them. This is the reason why you don't want to serve file-systems from shared arrays with ucarp or keepalived.
LinuX Containers is an operating-system-level virtualization method for running multiple isolated Linux systems (i.e. containers) on a control host using a single Linux kernel. Containers offer an environment as close as possible as the one you'd get from a VM but without the overhead that comes with running a separate kernel and simulating all the hardware.
The Linux kernel provides :
lxc-create --template download --name myContainer
https://wiki.debian.org/LXC#Changes_between_.22Jessie.22_and_.22Stretch.22
echo 'USE_LXC_BRIDGE="true"' >> /etc/default/lxc-net
systemctl status lxc
● lxc.service - LXC Container Initialization and Autoboot Code
Loaded: loaded (/lib/systemd/system/lxc.service; enabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:lxc-autostart
man:lxc
systemctl start lxc
lxc-checkconfig
Everything should be stated as "enable" in green color. If not, try to reboot the system.
https://wiki.debian.org/LXC#line-1-6
lxc-create --name ubuntu -t download
Setting up the GPG keyring
https://superuser.com/questions/399938/how-to-create-additional-gpg-keyring
gpg --no-default-keyring --keyring trustedkeys.gpg --fingerprint
https://linuxcontainers.org/lxc/manpages/man1/lxc-create.1.html
lxc-create --name ubuntu -t download -B best
Setting up the GPG keyring
ERROR: Unable to fetch GPG key from keyserver.
lxc-create --name ubuntu -t download -B best --logpriority=DEBUG
https://bugs.launchpad.net/openstack-ansible/+bug/1609479
https://review.openstack.org/#/c/350684/3/defaults/main.yml
# The DNS name of the LXD server to source the base container cache from
lxc_image_cache_server: images.linuxcontainers.org
# The keyservers to use when validating GPG keys for the downloaded cache
lxc_image_cache_primary_keyserver: hkp://p80.pool.sks-keyservers.net:80
lxc_image_cache_secondary_keyserver: hkp://keyserver.ubuntu.com:80
wget hkp://keyserver.ubuntu.com:80
https://doc.ubuntu-fr.org/apt-key
https://cran.r-project.org/bin/linux/ubuntu/
gpg --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys E084DAB9
nc -vz p80.pool.sks-keyservers.net 80 11371
nc -vz keyserver.ubuntu.com 80 11371
nmap -sT www.google.com -p 80,443
nmap -sT keyserver.ubuntu.com -p 80,11371
As :
myDomain.local type: kerberos realm-name: MYDOMAIN.LOCAL domain-name: myDomain.local configured: no server-software: active-directory client-software: sssd required-package: sssd-tools required-package: sssd required-package: libnss-sss required-package: libpam-sss required-package: adcli required-package: samba-common-bin
t_anderson@metacortex.com:*:919801223:919800513:Thomas ANDERSON:/home/t_anderson:/bin/bashIf you get an answer like that, it's ok
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022' | sudo tee -a /etc/pam.d/common-session%domain\ admins@myDomain.local ALL=(ALL) ALL' | sudo tee -a /etc/sudoers.d/domain_adminsuse_fully_qualified_names = False
simple_allow_groups = list,of,AD,groups,allowed,to,login
mountPoint='/home/bob/googleDrive'; mkdir "$mountPoint"; google-drive-ocamlfuse "$mountPoint"
On the first time, this will open a browser window to check permissions.
Check : mount | grep -q "$mountPoint" && echo 'GOOGLE DRIVE IS MOUNTED' || echo 'GOOGLE DRIVE NOT MOUNTED'
Galera cluster load balancing http://galeracluster.com/documentation-webpages/loadbalancing.html Cluster deployment variants http://galeracluster.com/documentation-webpages/deploymentvariants.html An Introduction to HAProxy and Load Balancing Concepts https://www.digitalocean.com/community/tutorials/an-introduction-to-haproxy-and-load-balancing-concepts
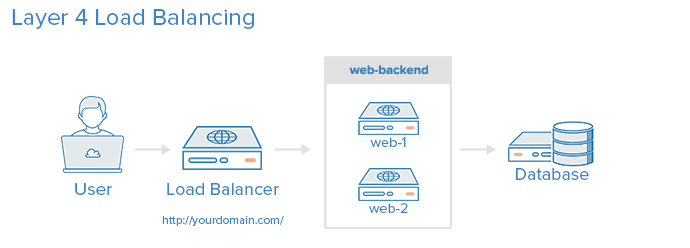
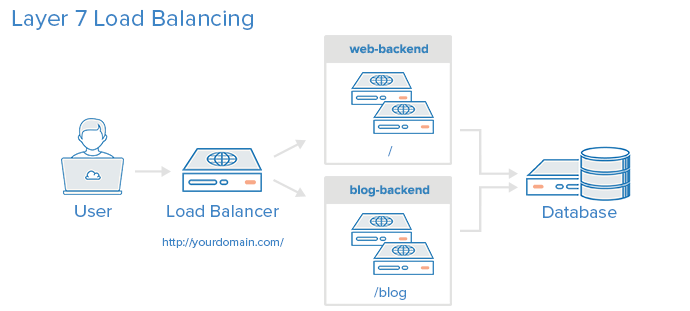
The load balancer itself mustn't be the SPOF of the infrastructure. This is why it has to become highly available via redundancy :
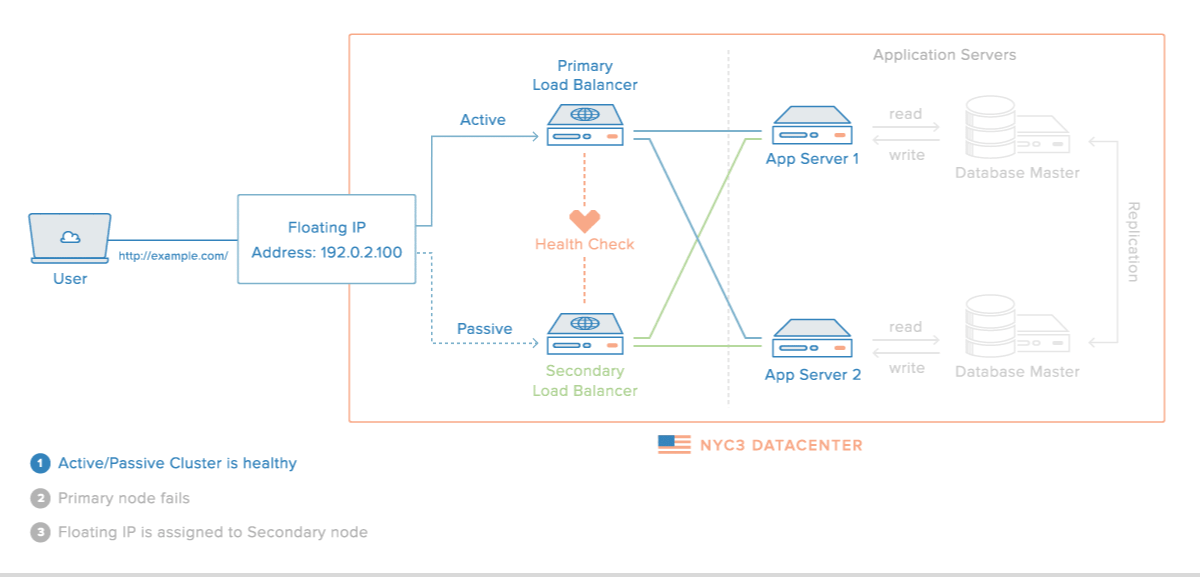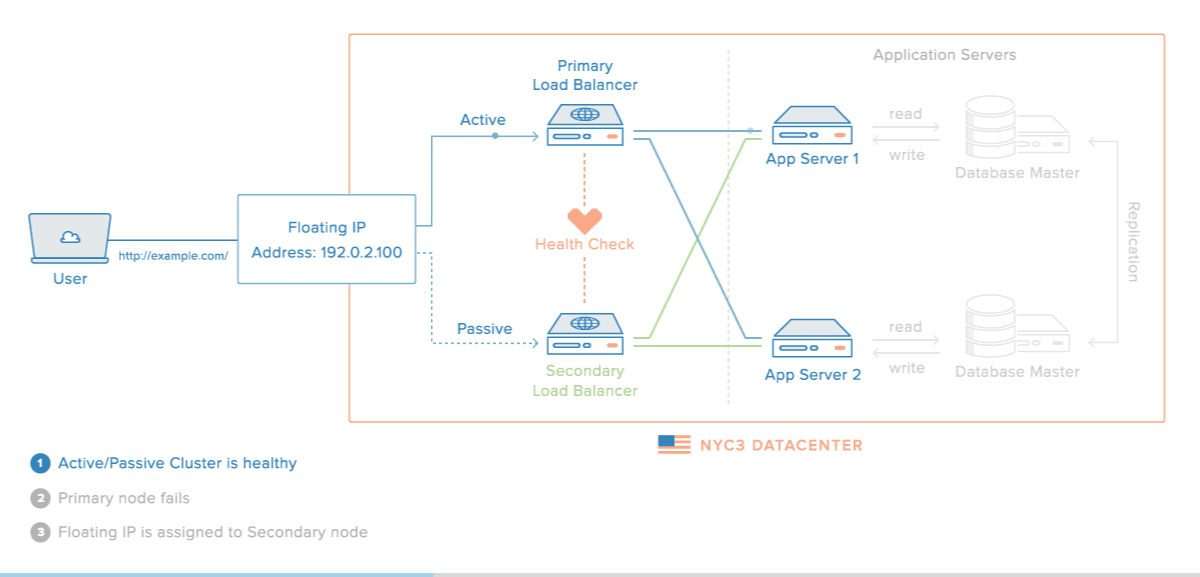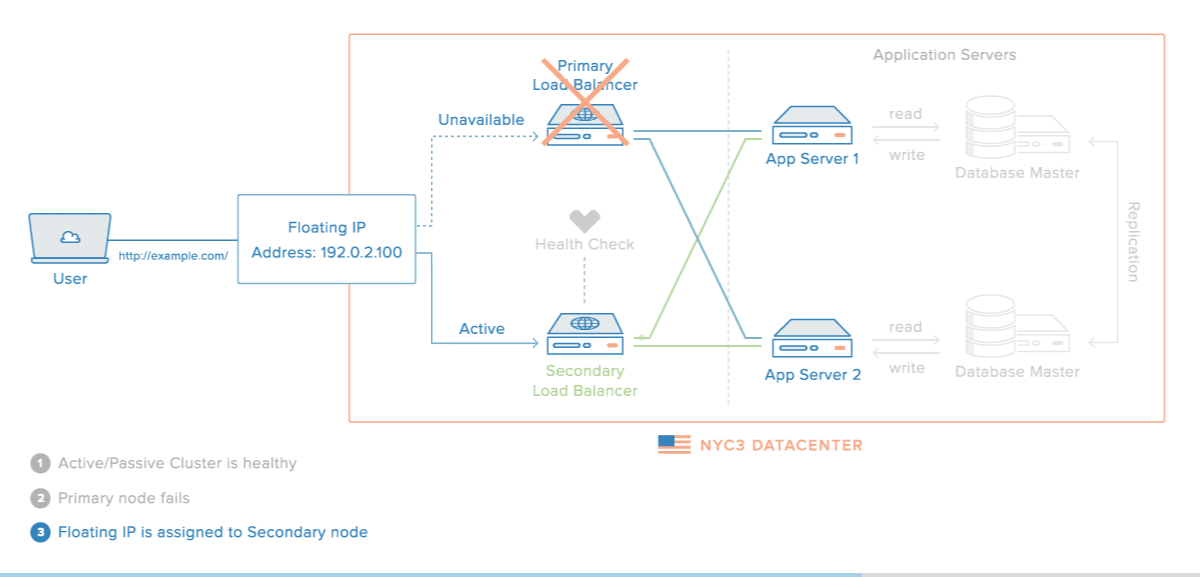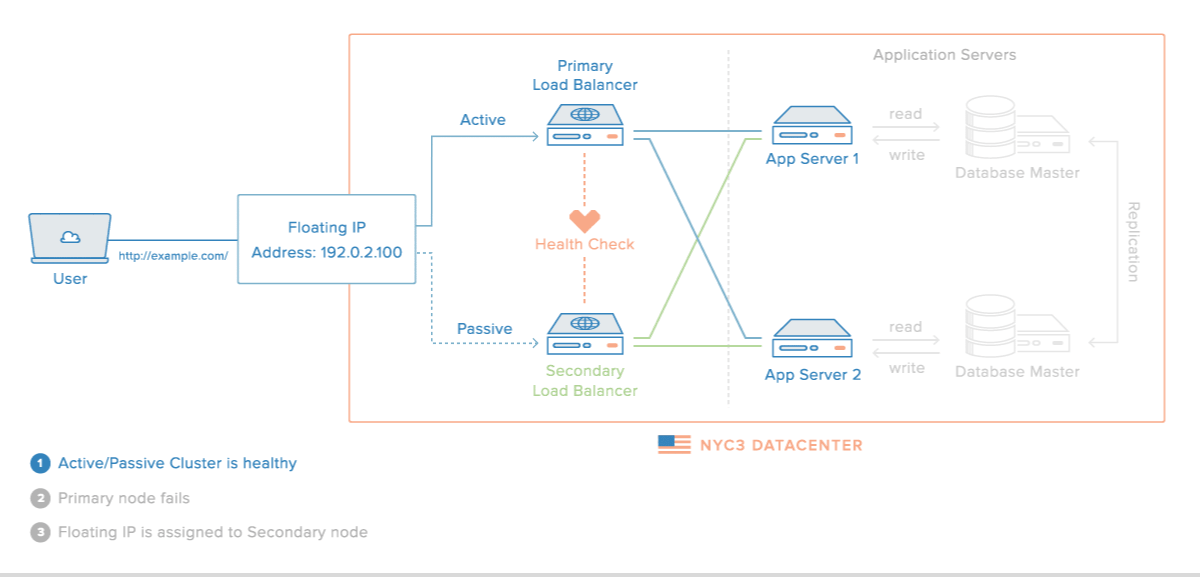
This can be achieved with tools such as :
{kind=link}